
{kind=link}
If you’ve ever stared at your profiler, watching your CPU choke on a bottleneck while your AMD GPU just sits there doing nothing, AMD might have just handed you the solution, and it doesn’t require becoming a GPU programming expert overnight.
AMD just announced hipThreads, the newest addition to its ROCm/HIP ecosystem, and the pitch is surprisingly straightforward: it’s a C++ style concurrency library that lets developers already using std::thread patterns port their code to AMD GPUs using the familiar hip::thread, making it possible to move C++ codebases to GPU execution incrementally, without a massive upfront investment.
In other words, you don’t have to throw away your existing code and start from scratch.
Same code, completely different power
The real genius of hipThreads is how little you actually have to change. The three-step migration process goes from a standard std::thread CPU baseline, to a drop-in GPU replacement with minimal changes, to a fully optimized version leveraging the GPU’s SIMD architecture, and the total code changes between step one and step three amount to just 16 lines.
The similarity between the CPU and the optimized GPU implementation sits at 96%.
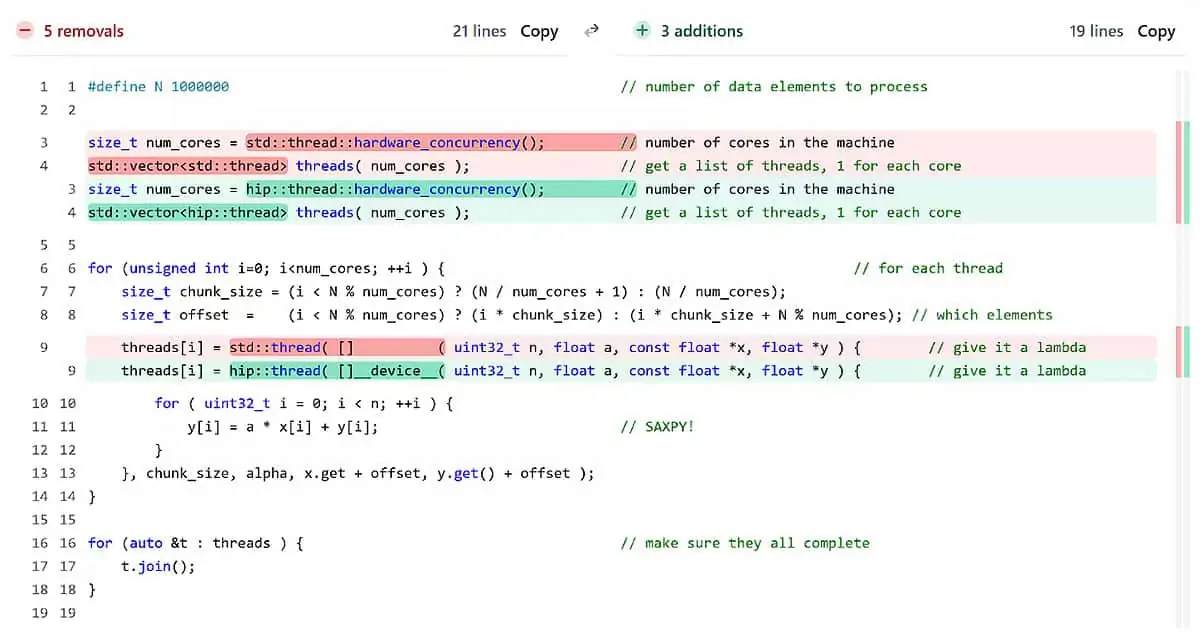
That’s not a typo. Ninety-six percent of your code stays the same.
Each hip::thread can also run with multiple “fibers”, parallel execution lanes that work together within a single virtual thread, taking advantage of the GPU’s SIMD architecture.
A hip::thread on AMD hardware typically uses a width of 32 fibers, which is conceptually similar to AVX-512 on CPUs, but with significantly wider data parallelism.
Who is this actually for?
AMD is being pretty direct about the target audience here. hipThreads is designed for C++ teams hitting CPU bottlenecks with clear hotspots in their profiler, developers without GPU expertise who can’t justify the time to learn CUDA or ROCm from scratch, and tool vendors who want simple GPU integration for their users.
The promise is compelling: use your existing C++ threading knowledge, port hotspots incrementally, and see results in days, not months. No need to learn grids, blocks, or warps. No need to hire a GPU specialist or spend months refactoring production code.
Testing by AMD in February 2026, using an AMD Radeon AI PRO R9700 with ROCm 7.0.2 on a system powered by a Ryzen 9 9900X and Ubuntu 24.04.2 LTS, showed real speedup results using hipThreads on the GPU versus standard threads on the CPU, validated through ray tracing and sparse matrix multiplication workloads.
Whether hipThreads becomes the bridge that finally makes AMD GPU compute mainstream for everyday C++ developers remains to be seen, but the approach, meet developers where they already are, is a smart one.
The GPU has always been sitting there waiting. Now there’s fewer excuses not to use it.
What do you think, is hipThreads the push GPU programming needed to go mainstream, or just another abstraction layer that trades performance for convenience? Drop your take below, we want to hear from you!